Approaching the Singularity - CTF Writeup
Challenge Info permalink
This one was incredibly tough, and required me to experiment with new ways to solve problems and automate tasks. I'm quite proud of the result, and you'll hopefully see why by the end of the post.
+----------------+--------------------------------------------+
| CTF Name | 247CTF |
| Challenge Name | Mechanical Turk |
| Description | Solve 100 captcha equations in 30 seconds |
| Category | Web |
| Points | 310 |
+----------------+--------------------------------------------+
Part 1 - Investigation

On starting the challenge instance, we're met with a simple web page with a CAPTCHA and a form consisting of an input box and a submit button. Given that the page is so plain, let's check out the source and see if there's anything that could give us insight into how the CAPTCHA is generated, and if we can modify anything.
At a quick glance, there's nothing actually being loaded remotely in terms of scripts, i.e. no JavaScript. The only thing that's loaded is the CSS, which isn't interesting at all.
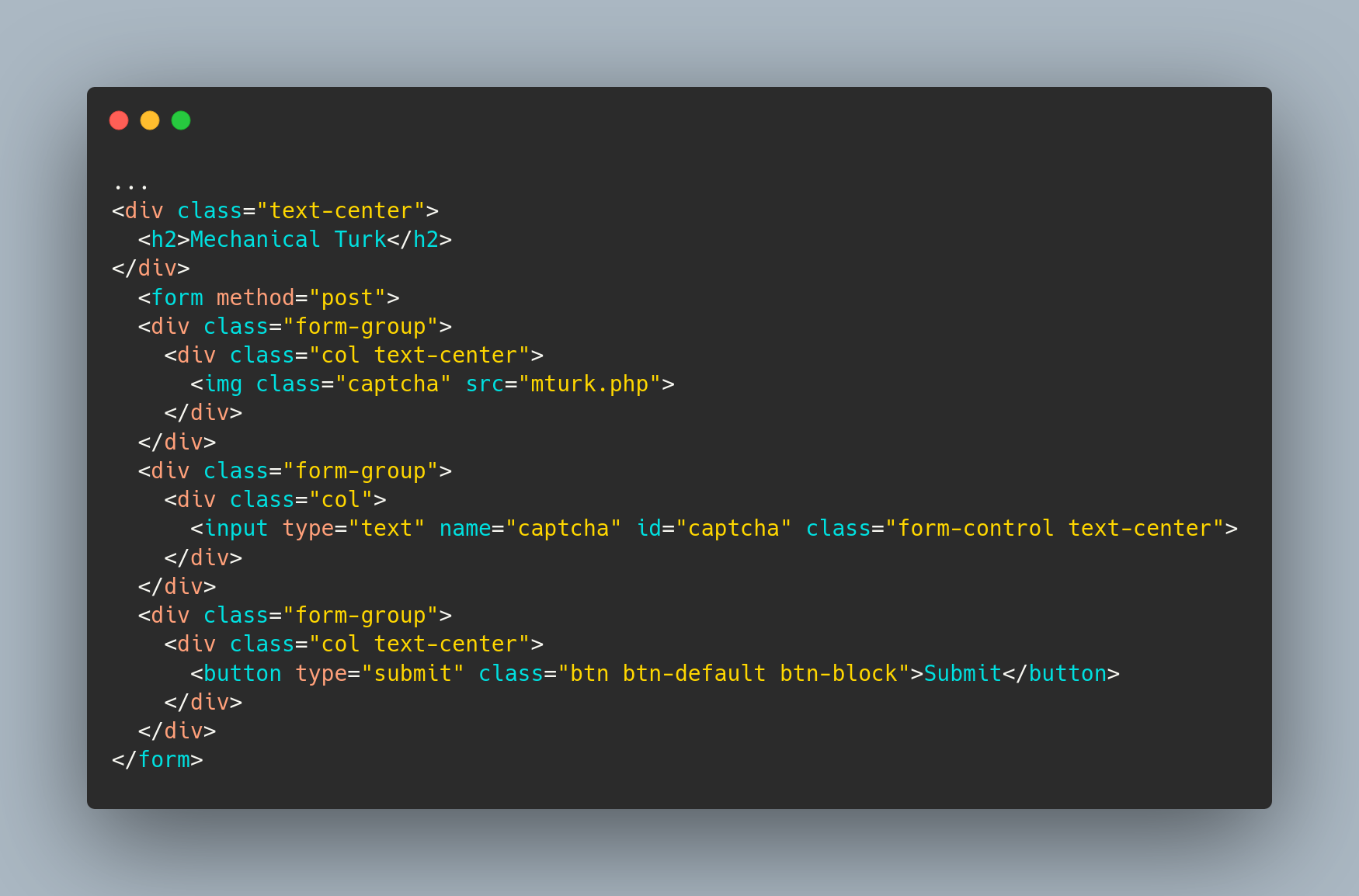
Given that there's nothing of interest in the head, let's focus our attention on the body. The body of the page is, again, very simple - only loading an image from mturk.php and a form which on submission, sends a POST request to the page with the data entered into the text field.
We can now rule out any form of JavaScript nonsense and focus our attention on what data is actually sent to and received from the server. Setting up a HTTP Proxy which intercepts requests is the best way to do that, and we'll use Burp Suite for that.
Burp Suite permalink
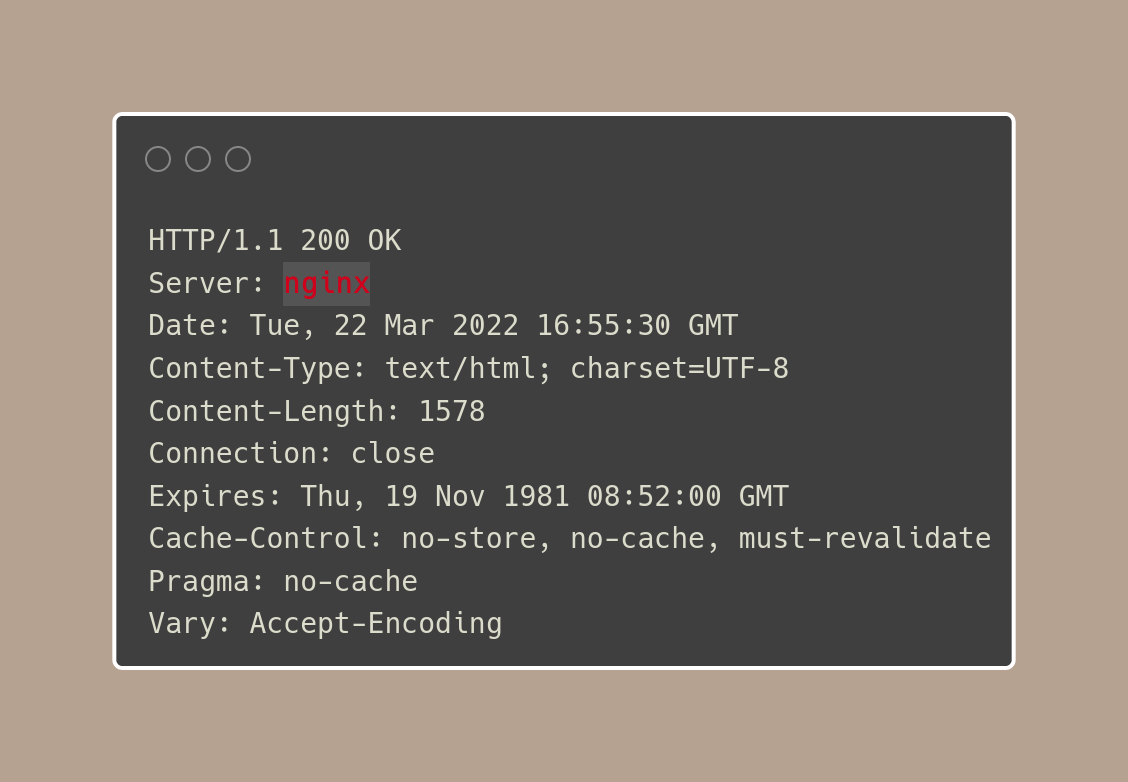
Loading the page -
GET /
Response
Sending data -
POST /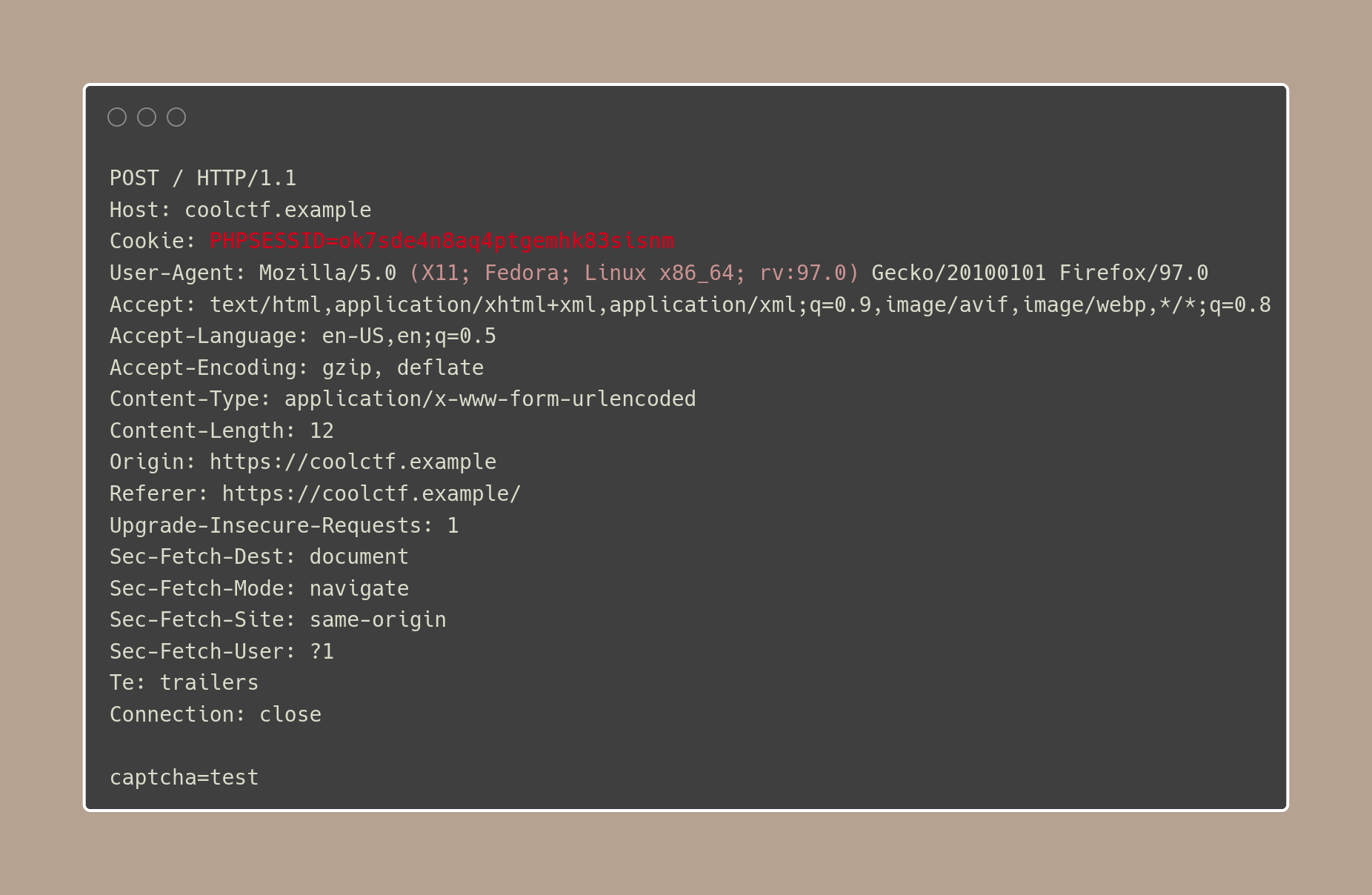
Response

From the two endpoints we've been able to hit, we've been able to see two pieces of evidence that may help us in solving this.
- The server is running on NGINX (not super helpful)
- The site stores a PHP Session cookie (probably useful)
Knowing this, we're more likely to be able to programmatically solve the CAPTCHAs, as we'll need the session ID to tie our POST requests to the CAPTCHA image we've received.
If we move our attention to mturk.php, the file which is rendered as an image, we'll see that it is actually just a PNG file which is generated on each call to the page.
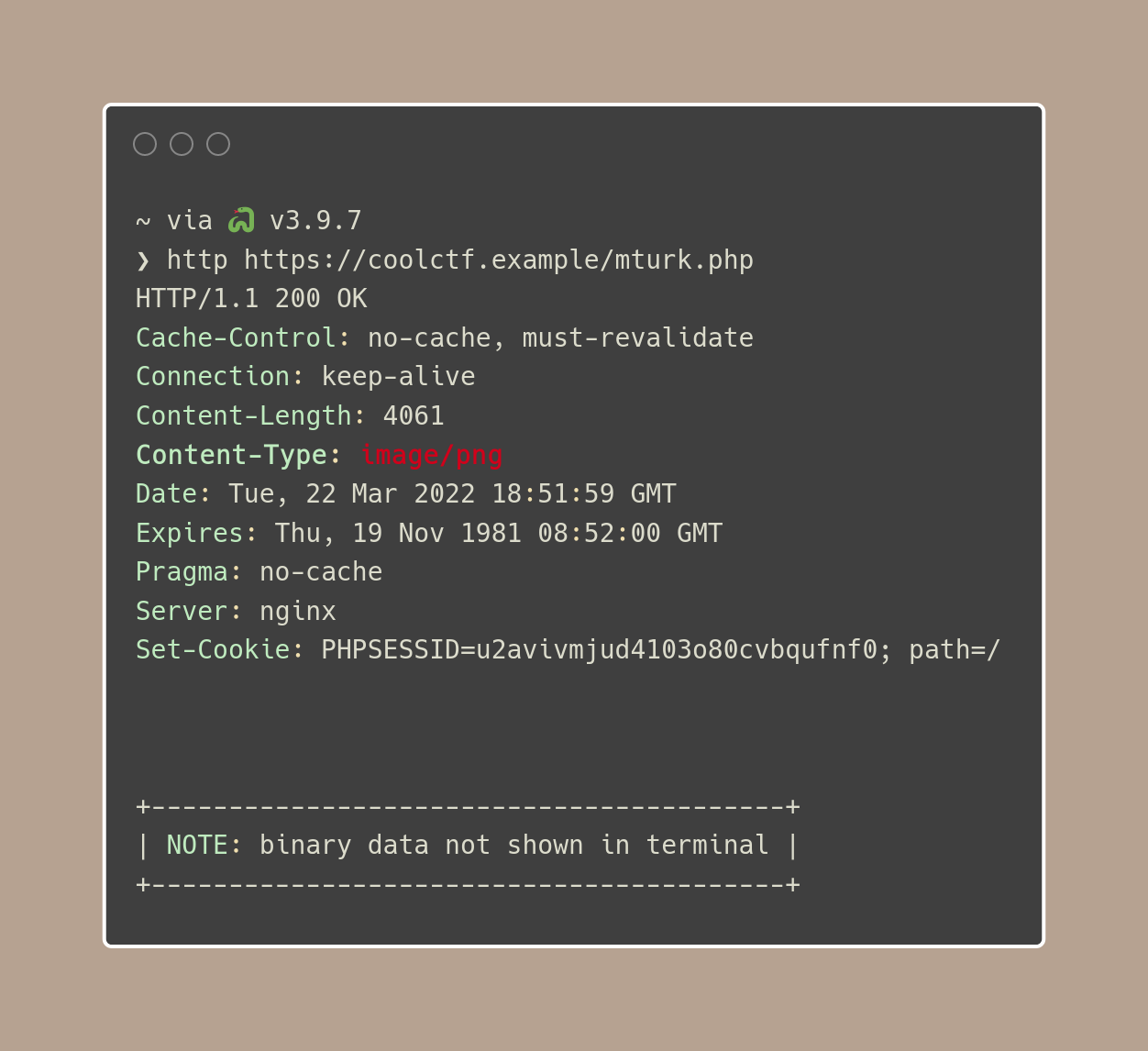
A couple calls to mturk.php proves this and yields these results.

With no obvious headers or request body items to influence what CAPTCHA is actually generated on each call, we can easily assume that we can't make the CAPTCHA generate what we want and that it's done randomly each time the endpoint is hit.
This is going to be tricky.
CAPTCHA Background permalink
If you cast your mind back to the start of this blog, you'll see that CAPTCHA is actually an acronym (or maybe a backronym) for "Completely Automated Public Turing test to tell Computers and Humans Apart". To truly understand what that means, let's quickly describe what a Turing Test is.

A Turing Test is a method of testing whether or not an Artificial Intelligence (AI) is capable of thinking like a Human. During the test, a Human test subject and an AI interact with a Human observer who is asking questions. The AI and the human are both asked the same questions, within the same specific subject and the same format. The observer, after having asked the questions must then determine which answers were the Human's, and which were the AI's. This process is repeated a number of times, and the AI is deemed to have passed the Turing Test if the observer is incorrect 50% of the time or more. To date, no computer or AI has been able to pass the Turing test.
CAPTCHA's purpose is to tell Humans and Computers apart. There are a number of great reasons why you should do this, but mainly it's there to prevent Botting - the running of tasks in a repeated manner by a computer, sometimes maliciously.
You, the test subject reader, have undoubtedly come across CAPTCHAs in one way or another. If you're signing up to a new website, using Google over a company VPN, or have simply visited a web page one too many times.
CAPTCHAs are specifically designed to be unreadable by OCR (Optical Character Recognition) tools, meaning that Computers should not be able to read them. They make use of warped characters on low-contrast backgrounds, sometimes with arbitrary shapes around to make this task even more difficult. Upon completion of a CAPTCHA, the web application knows with some degree of confidence that the user attempting to access it is in fact a human.
Except that's not so true nowadays.
Part 2 - Neural Networks
Yes, it's a bit of a buzzword nowadays, but Artificial Intelligence, Machine Learning and Neural Networks are terms that are at the forefront of modern computing, and they'll be around for a while. The only issue is, Corpo rats have gotten their hands on it and are applying it to everything, without really understanding what it is or how it works. AI-powered Washing Machines, ML for trading, it's all a bit reminiscent of when IoT first became a thing. Who needs an internet connected fridge that can think?
Rant over. While AI as a subject is waved around as a sales pitch, it can actually be quite useful. Pattern recognition in images is such an incredibly broad field with millions of potential applications. Diagnosing illness with medical scans, image description for the sight impaired, collision detection in self-driving cars and even hand tracking for VR/AR (yay, more buzzwords) applications are just a small number of applications that are in place in the real world that are powered by Neural Networks.
Previously, these would have required absolutely massive data sets to train from, and an inordinate amount of time to perform the training and subsequent inference or predictions, but with advances in parallel processing, both of these variables have been vastly reduced. Modern frameworks like Tensorflow and Keras can transparently make use of GPU cores to accelerate the parellel processing workloads required to build Neural Network models. But you didn't come here for a lesson or a sales pitch.
The only way I could realistically see myself solving this challenge was either paying a bunch of Comp Sci students in pizza to access a proxied version of the challenge site (i.e. sharing the PHP Session Token), and hoping they'd be fast enough to beat the 30 second limit, or building a prediction model which could accurately "read" the CAPTCHA text and solve the equation given.
I went for the latter option, as I'm broke and I don't think I could trust students without being in the room with them.
And so I went off and attempted to build a model. I ended up using Keras' own example for CAPTCHA OCR, which cut out most of the hard work for me. I won't bother adding the code for the model to this blog, as it's long, verbose and it's not my own work. You'd also get a better appreciation for it by following the Keras example.
This is where I ran into my first major issue. The Keras example assumes you already have a training dataset ready to plug into the model, based on an already existing library of CAPTCHA images, with each being labeled with the CAPTCHA text. Great, I thought, and then I realised mturk.php's text was too different to be able to infer from that dataset.
So I had to build that one myself...
Part 3 - Training
And off we go, a seemingly endless cycle of "Right-click, Save Image, Name the file, Refresh, Repeat". After about 45 mins, I'd amassed a grand total of 60 images. That should be enough to train the model, right?
Firstly, let's make sure that our dataset looks right. That's a great starting place to make sure that what we're working with makes sense to not only the computer, but also to us once we're done with it.

Giving the dataset 100 Epochs (100 rounds of passing all data through the model once, forwards and backwards, to train the model to fit the expected output), and 60 images to work from, we get this output which I like to call Gen 0.

I don't know about you, but getting any more images than that using the "right-click, save-as" method sounds like a rough estimation of what punishments await me in hell. There had to be a better way to do it, but regardless there had to be some human input at some point, purely by virtue of us not yet having a system to read the images. That's what we're building, after all.
So I broke out the Python and wrote a little app to make my life easier.
Python App permalink
The easiest way I thought of setting this up was by using a Flask app with two endpoints, one to display the page, and another to send the filename and image data to. Let's code that as we go.
We have the bare-bones now, but we also need a webpage to display and interact with. Using Flask, we can actually do this in Jinja quite easily
So now we have a super simple page which is dedicated to filling in CAPTCHAs, as well as showing how many images you've spent your time filling in. It's like a really shit cookie clicker.

Getting the UI and endpoints set up was the easy part, the hard part was now actually performing the process of:
- Displaying the image
- Taking the filename
- Writing the image to disk with the filename
all while making sure we're working on the same image. Remember, each time mturk.php is called, a new image is generated, so we can only call down the image once.
If we break down each step, the task seems a lot more manageable than at first glance.
Rendering the Jinja template seemed difficult, as you can't pass binary data to HTML and render it as an image. Then I remembered that you can, but only if you Base64 encode the image data into plaintext. In order to do this, we need to edit the j2 template we made previously so that the img tag knows how to read the data.
Except now the issue is how do we pass the image data from the GET route, to the POST route that saves the file. The answer is, send it with the POST request. You can create a hidden input which sends the image data to the POST endpoint, which can then be decoded and turned back into an image.
So we've worked out how to display and pass data from the HTML perspective, let's actually get these routes doing something.
A few more imports gets us all the tools we need to finish this off.
Once we populate all the routes and plumb them together to create our Load-Solve-Submit pipeline, we get something that looks like this.
Model permalink
Now that we've got our Flask app for grabbing images, we can now (manually) label our dataset. I found that 400 images got us the best results. Training at 200 Epochs with a stopping patience of 100 got us to the point of being able to reliably enter those 100 captchas.